×
JCtrans升级通知
客户您好
为保障数据安全和防止用户间操作冲突,我们现更新:
同一个站点1个账号同一时间仅允许1人在线(就是只能在一个设备上登录,若同时在其他设备登录,先前登录的用户会被提醒:您的账户已在其他设备上登录)。
若有疑虑问题,请与平台客服工作人员联系。
显示样式:

如想多人登录,可通过注册子账号实现。
子账号注册流程:
第一步:使用主账号登录hi.jctrans.com,点击菜单中的“企业账号管理”
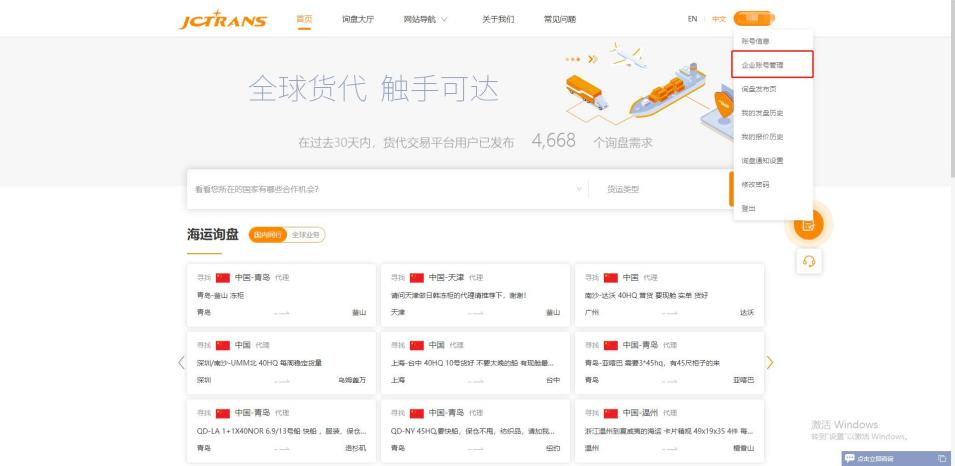
第二步:点击“新建子账号”
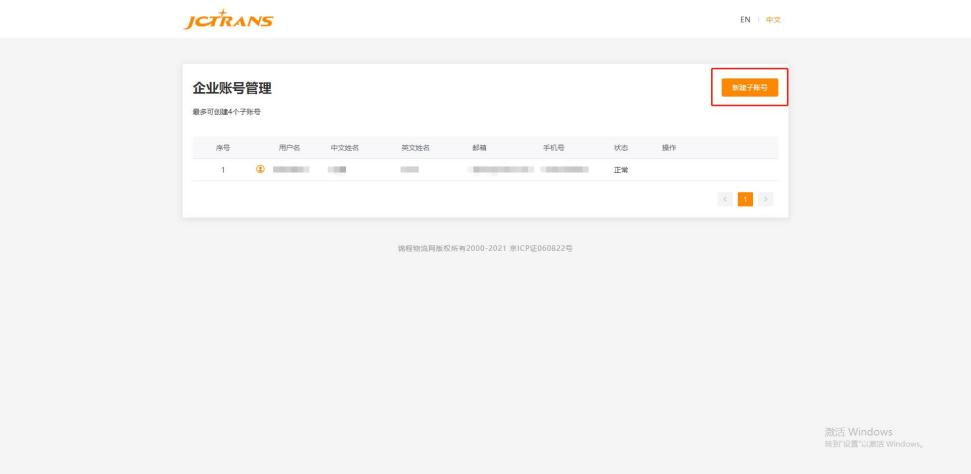








.jpg)




国际物流有限公司 648-250公司名字橙色.jpg)

有限公司 648-250.jpg)


有限公司 648-250(1) 伊朗 俄罗斯 土耳其.png)

.jpg)






.jpg)
.jpg)
.jpg)
.jpg)





.jpg)
(4).jpg)




.jpg)

(1).jpg)
.jpg)

1200x120(1).jpg)

.jpg)


.jpg)


.jpg)
.jpg)

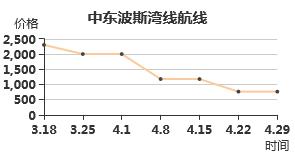
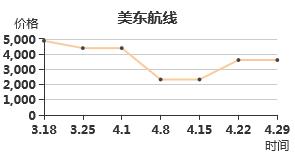




 京公网安备 11010802025331号
京公网安备 11010802025331号







